
About
I am a first-year Ph.D. student in EECS at UC Berkeley, affiliated with Berkeley AI Research (BAIR) and Sky Computing Lab. My research is advised by Prof. Trevor Darrell and Prof. Joseph Gonzalez. I am interested in multimodal interactive intelligence. I am currently a research scientist intern at Meta Superintelligence Lab
Previously, I worked as a Member of Technical Staff at Voio, Inc, where I co-led multimodal post-training for vision-language models to understand and reason about volumetric radiology scans. I obtained B.S. in Data Science at the Halicioglu Data Science Institute (HDSI) and B.A. in Cognitive Science at the CogSci Department at the University of California, San Diego (UCSD). I was advised by Prof. Zhuowen Tu and Prof. Zhiting Hu for generative models in computer vision during my undergraduate years. I obtained my M.S.E. in Computer Science at Princeton University, advised by Prof. Danqi Chen where I worked on multimodal pre-training, reasoning and evaluation. I am a recipient of Siebel Scholar, Class of 2025 in Computer Science and a member of the inaugural cohort of Delta Fellows.
Publications

We study Playful Agentic Robot Learning with RATs, an embodied coding agent that uses self-directed play as a continual skill-learning stage before downstream tasks arrive. RATs proposes novel yet learnable tasks, writes and executes robot-code policies, verifies progress, diagnoses failures, and distills successful executions into a persistent library of callable code skills that improve held-out tasks and transfer to other Code-as-Policy agents without finetuning.
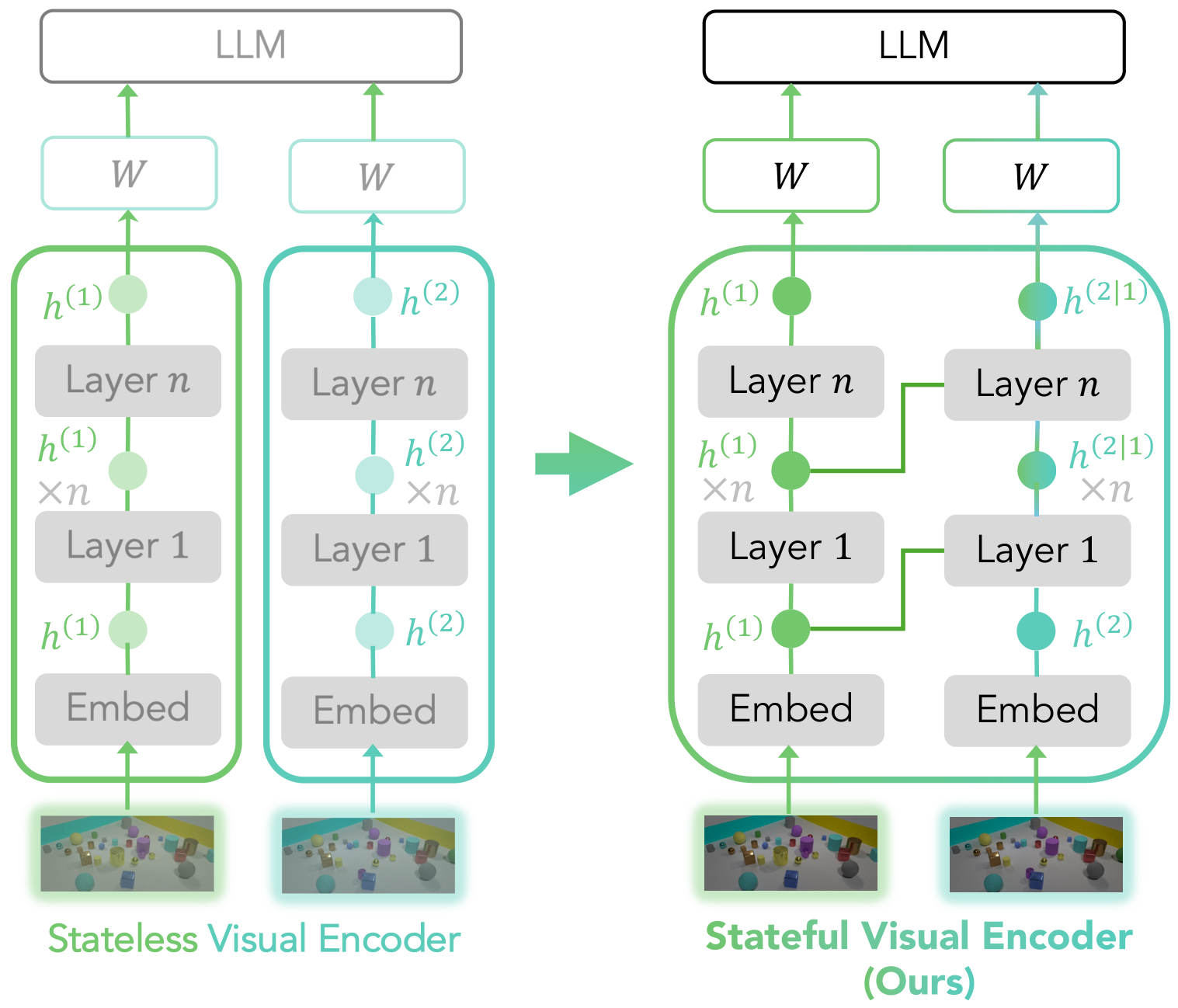
We introduce stateful visual encoders for vision-language models, where we condition visual representations of later images on those of previous images inside the visual encoder. This enables visual representations to be change-aware and improves vision-language models for multi-image reasoning and change understanding.
We introduce PixelRAG, a retrieval-augmented generation framework that indexes the web as rendered screenshot tiles rather than parsed text chunks. By retrieving pixels directly, PixelRAG preserves tables, layouts, and visual structure that text-based pipelines often lose, enabling reader models to answer questions that text-only RAG cannot.

We introduce polylithic systems, where independent producers contribute specialized capabilities to a shared agentic system. Our experiments show that coordinated specialists from multiple producers outperform monolithic generalists, and even small producers that underperform in isolation can improve the overall system by 5–13%.
ICLR Workshop on Multimodal Intelligence (Best Paper Award, top 1.2%), 2026
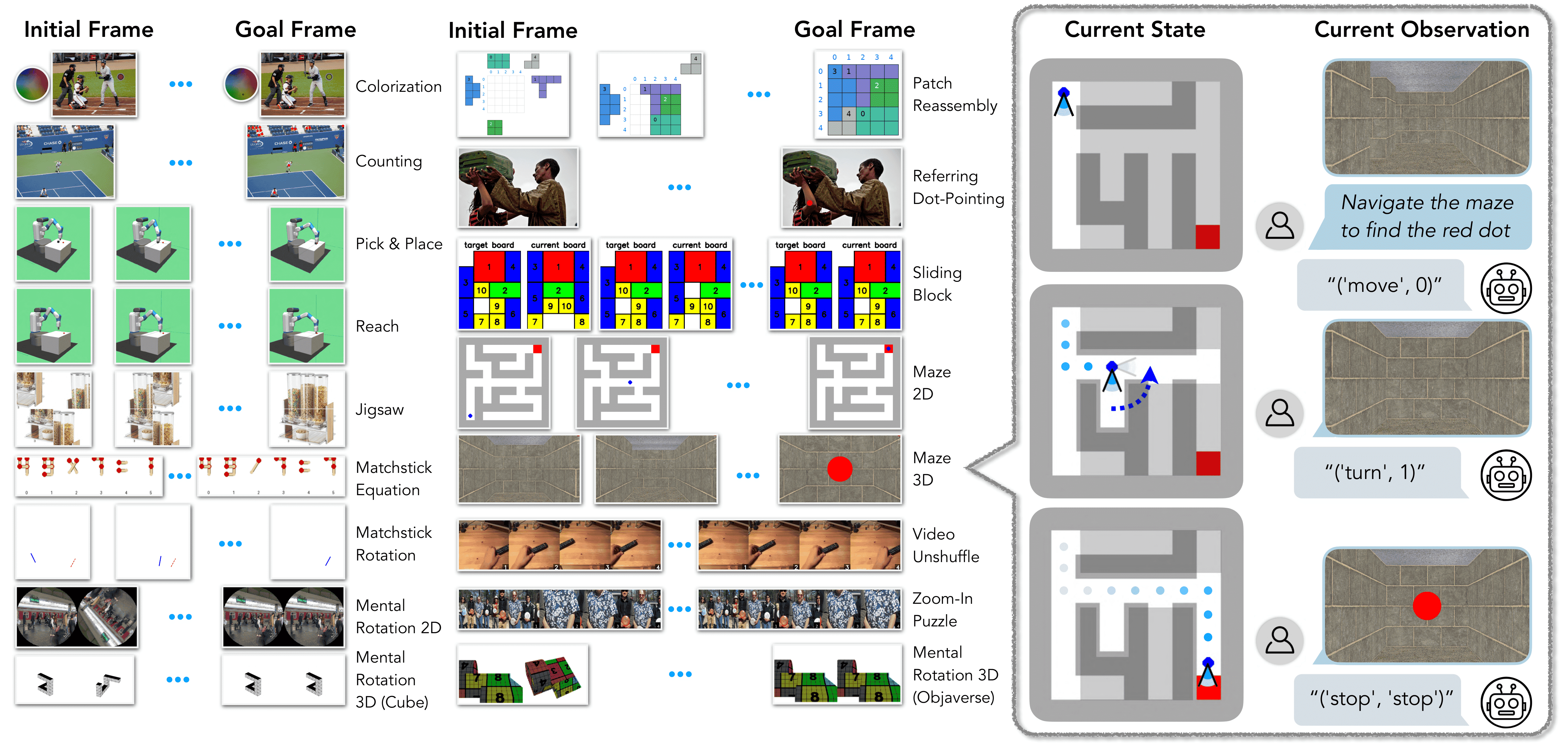
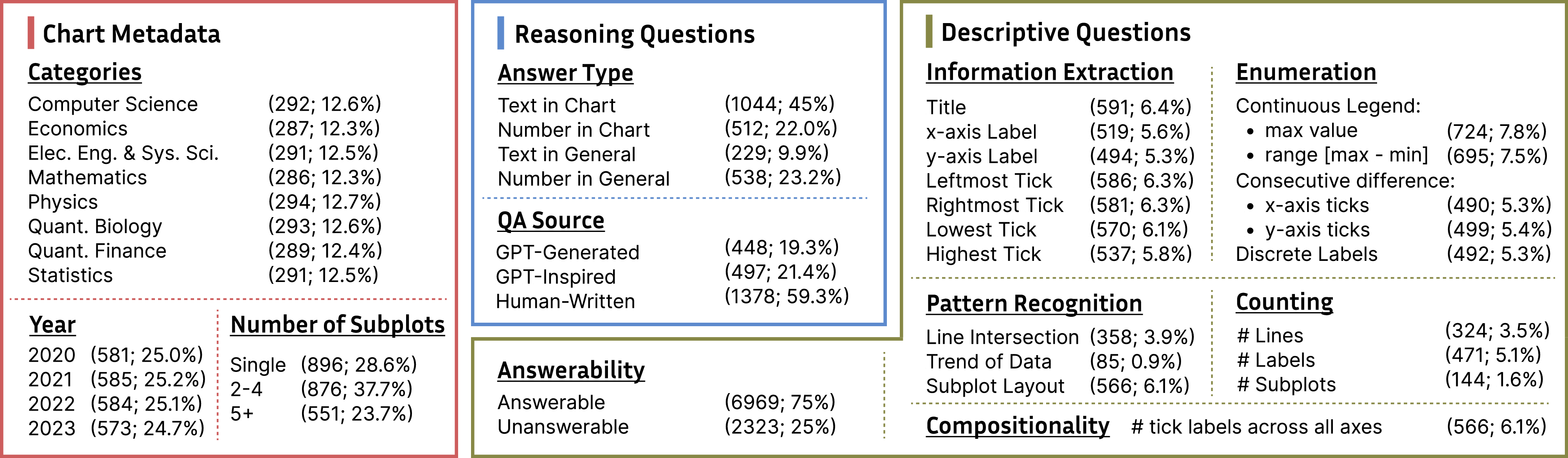
We introduce VisGym, a gymnasium of 17 environments for evaluating and training VLMs. The suite spans symbolic puzzles, real-image understanding, navigation, and manipulation, and provides flexible controls over difficulty, input representation, planning horizon, and feedback.
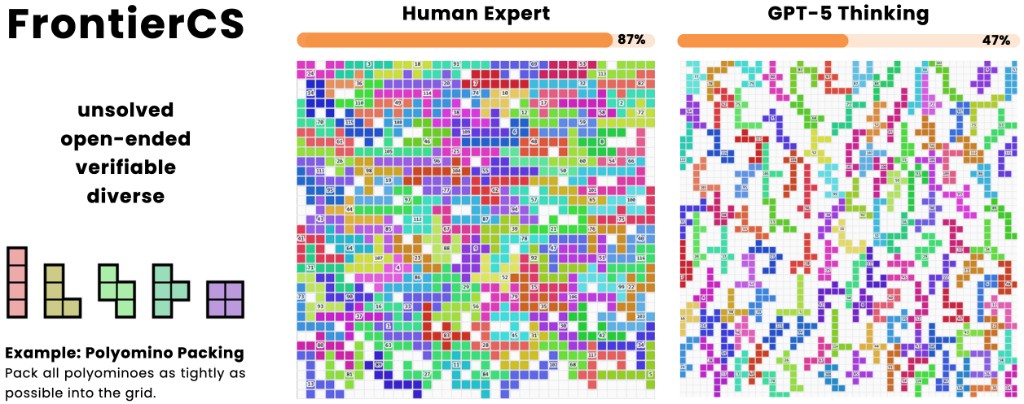
FrontierCS is a benchmark of unsolved, open-ended, verifiable, and diverse computer science challenges designed to evolve alongside AI capabilities, featuring problems like polyomino packing that remain difficult even for advanced models.
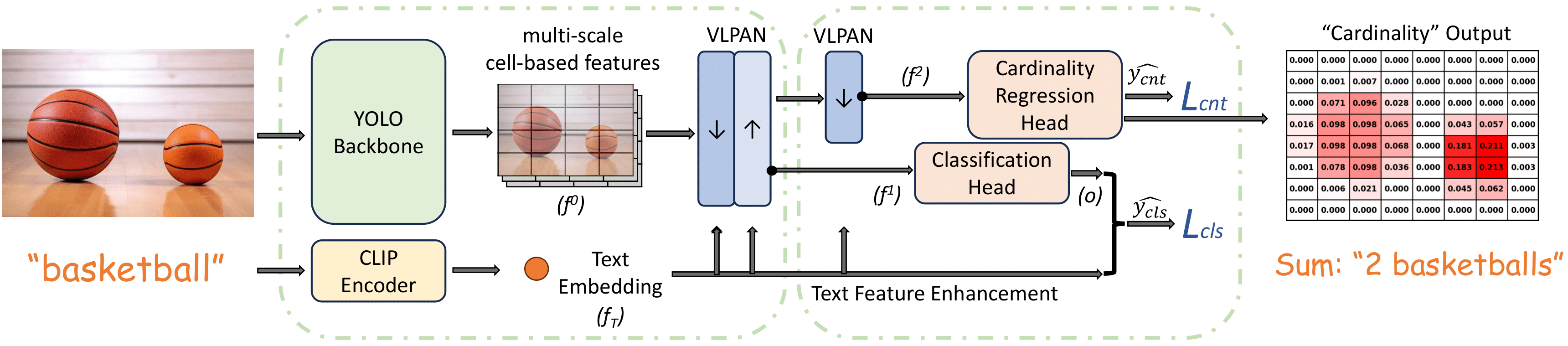
We propose YOLO-Count, a differentiable open-vocabulary object counting model that tackles both general counting challenges and enables precise quantity control for text-to-image (T2I) generation.
NeurIPS Workshop on Multimodal Algorithmic Reasoning (Spotlight)
ECCV Workshop on Emergent Visual Abilities and Limits of Foundation Models, 2024
CharXiv reveals significant shortcomings in MLLMs’ chart understanding, showing a large performance gap between models and humans.
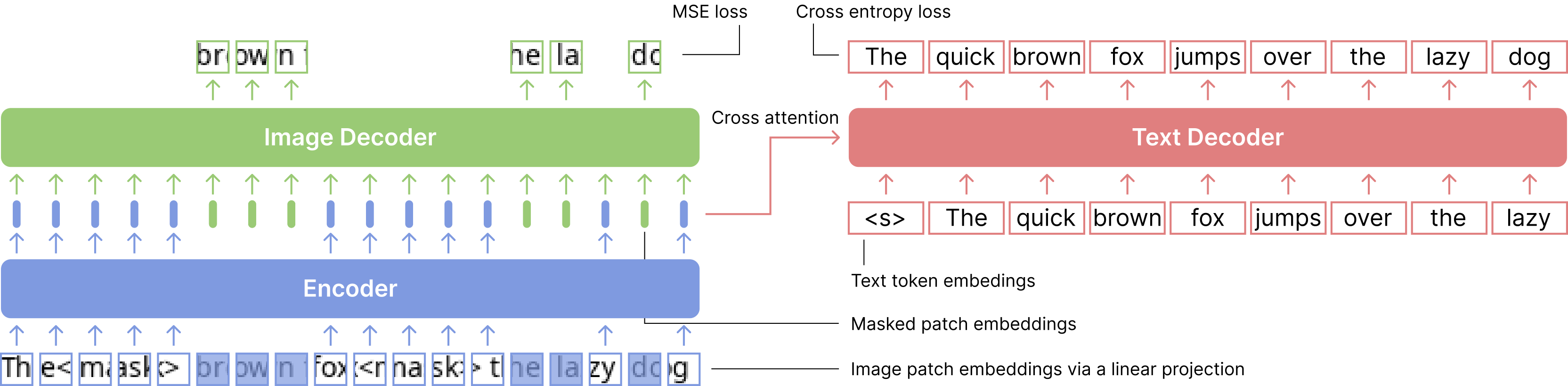
We close the performance gap between screenshot Language Models and text-only Language Models on language understanding tasks with our PTP objective.
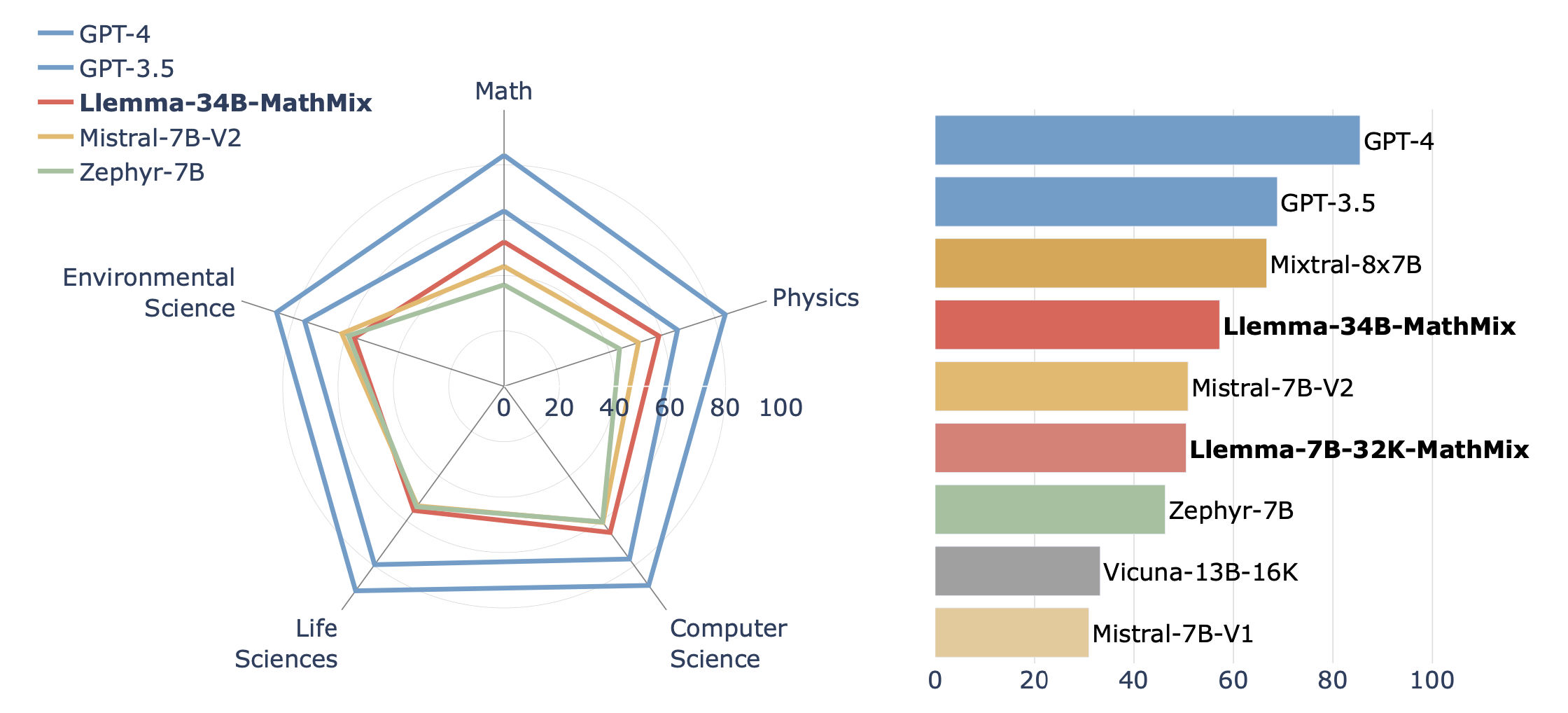
We propose TutorChat and TutorEval, a dataset of long synthetic dialogues about textbooks and a question-ansering benchmark consisting questions about long chapters from STEM textbooks written by human experts.
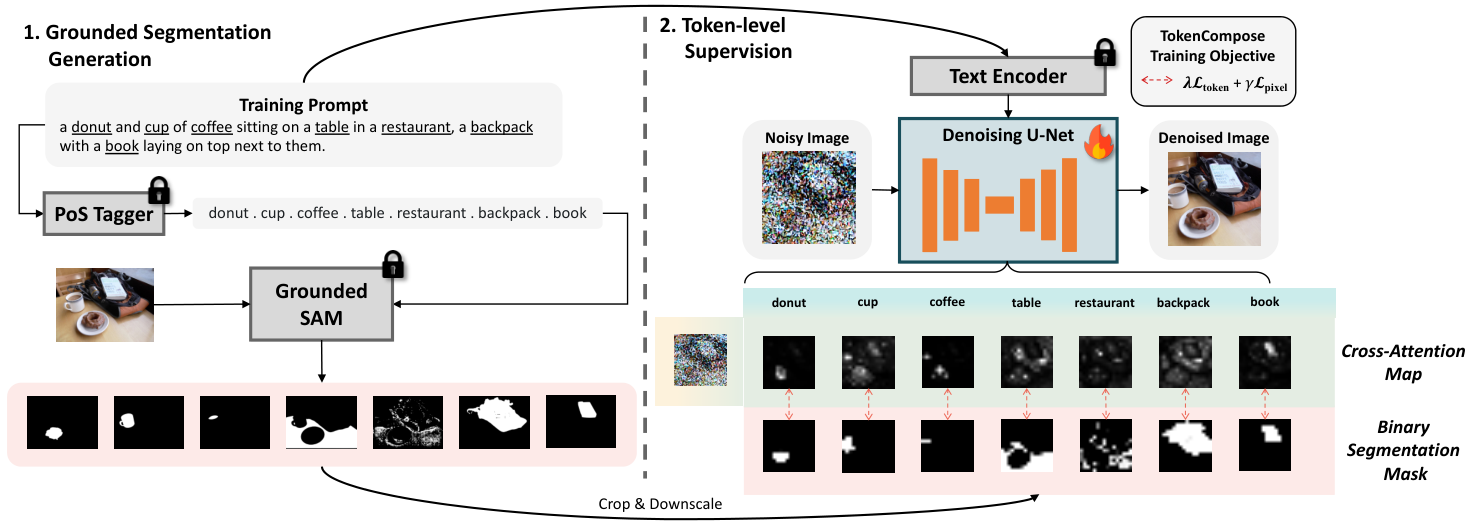
We introduce token-wise consistency terms between the image content and object segmentation maps in training text-to-image models for enhanced multi-category instance composition and photorealism.
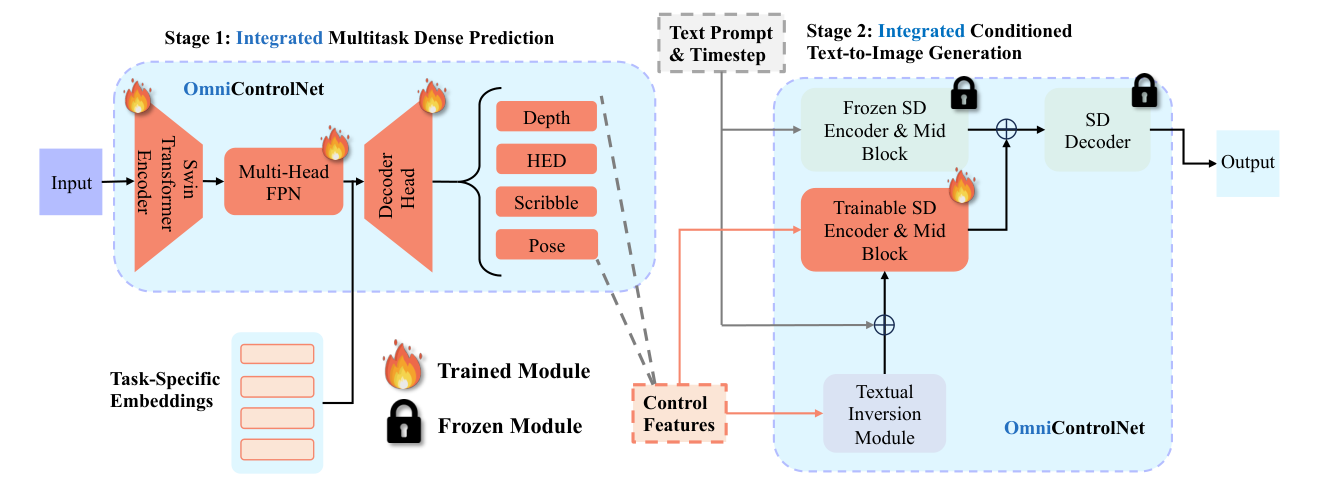
We provide a two-way integration for the widely-adopted ControlNet method by integrating four external condition generation algorithms into a single dense image labeling method, and by integrating its individually trained image generation processes into a single model.
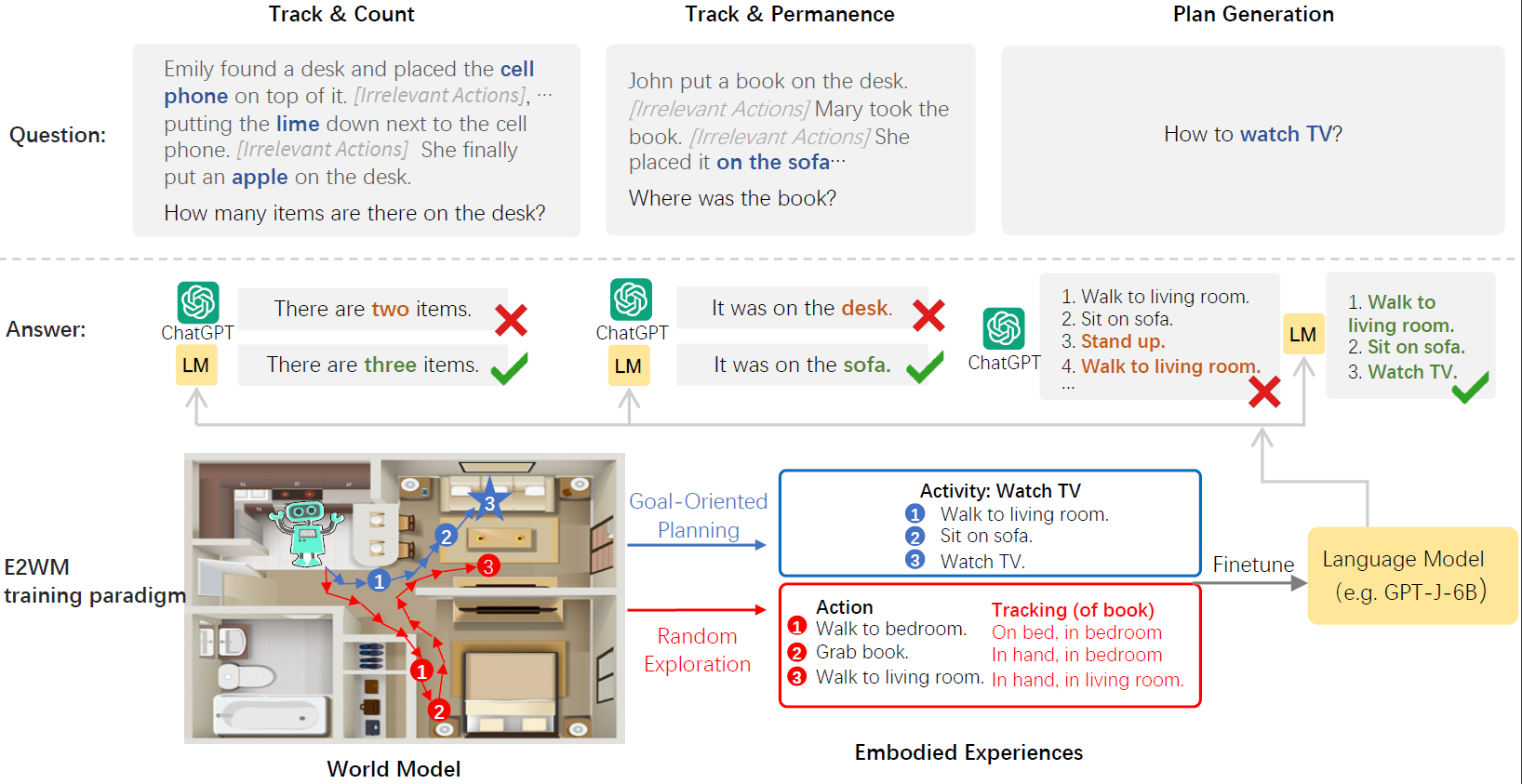
We establish a framework that effectively and efficiently finetunes a language model with embodied experience while retaining its language modeling abilities.
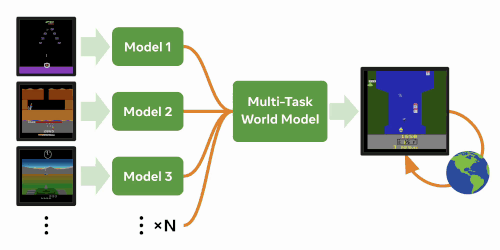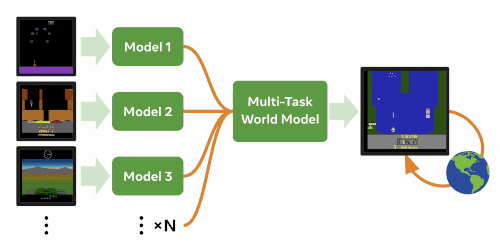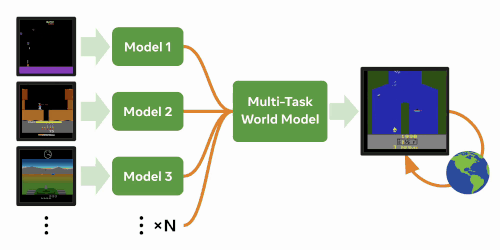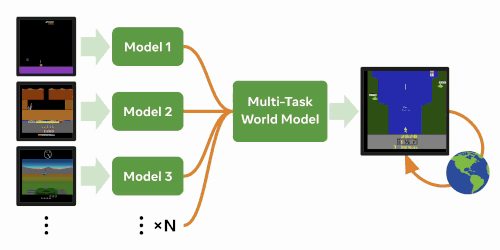
We investigate whether internal models learned by modern model-based RL algorithms can be leveraged to solve new, distinctly different tasks faster.
Services
📝 Conference Reviewer:
- International Conference on Machine Learning (ICML): 2024, 2025, 2026
- International Conference on Learning Representations (ICLR): 2024, 2025, 2026
- Conference on Neural Information Processing Systems (NeurIPS): 2024 🏆*, 2025
- Association for Computational Linguistics (ACL): 2025
- Conference on Computer Vision and Pattern Recognition (CVPR): 2025
- Association for the Advancement of Artificial Intelligence (AAAI): 2026
* Outstanding Reviewer
🎓 Alumni Interviewer:
- Princeton University, Class of 2030: 2026
Teaching









Misc
- 🏋️ I compete in powerlifting at 82.5kg. The physique? Just what happens when you spend too much time under a barbell.